
Natural Language Processing (NLP) often feels like magic: models capture the meaning of words and place them in a vector space where king — man + woman ≈ queen. But behind that magic lies a clever algorithm — Word2Vec (Visit the link to check it out on my GitHub).
Most tutorials build Word2Vec in Python with libraries like TensorFlow or PyTorch. But what if you had to build it from scratch in C++ — no frameworks, no shortcuts? That’s exactly the project I tackled, training Word2Vec on George R. R. Martin’s Song of Ice & Fire corpus (~298,000 tokens).
In this article, I’ll walk you through the process, design choices, and results.
Why C++?
C++ offers raw control over memory, performance, and computation — qualities often hidden behind high-level libraries in Python. By building Word2Vec in C++, I wanted to:
Understand the internals of tokenization, context windows, embeddings, and training.
See how forward pass, backpropagation, and SoftMax are built from the ground up.
Optimize for performance when scaling beyond toy datasets.
This project isn’t about convenience — it’s about learning by doing.
Step 1: Tokenizing the Corpus
The first step was breaking down text into words (tokens). I wrote a custom tokenizer in C++ that:
Reads words sequentially using while (file >> word).
Removes punctuation (so “How’s” :“hows”).
Converts everything to lowercase for consistency.
Example:
Input :“Hello! How’s NLP going?”
Output : [“hello”, “hows”, “nlp”, “going”]
This simple preprocessing ensures a clean vocabulary before training.
Step 2: Building the Vocabulary
Each unique word in the corpus is assigned an index using an unordered_map for O(1) lookups.
Why unordered_map? Faster search and insertion compared to ordered maps, which is critical with nearly 300k tokens.
Step 3: Context–Target Pairs (CBOW)
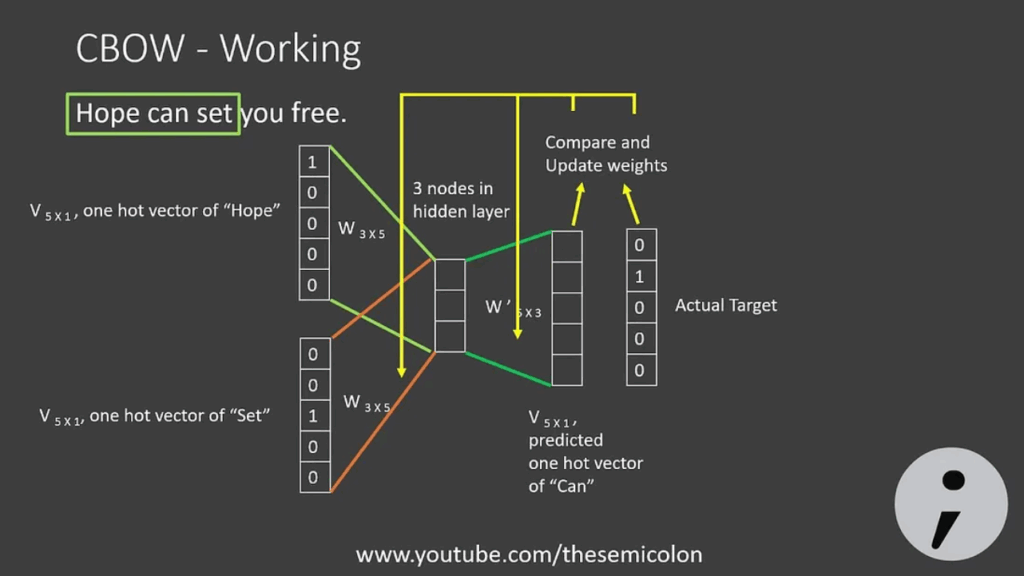
I used the Continuous Bag of Words (CBOW) algorithm.
CBOW predicts the target word given its context words.
Example sentence: “My name is Eshvar Balaji”
Window size = 2
Target = “is”
Context = [“my”, “name”, “eshvar”, “balaji”]
Why CBOW over Skip-gram?
CBOW performs better on smaller datasets like mine.
Skip-gram works well for large corpora but is slower to train.
Step 4: Initializing Weight Matrices
Word2Vec relies on two matrices:
W1: (vocab_size * embedding_dim)
W2: (embedding_dim * vocab_size)
Both are initialized with random values ( srand(time(0)) ).
These matrices will eventually become the word embeddings after training.
Step 5: Forward Pass & SoftMax
The forward pass works like this:
Input one-hot vector × W1 → hidden layer.
Hidden layer × W2 → raw scores (logits).
Apply SoftMax → probability distribution across the vocabulary.
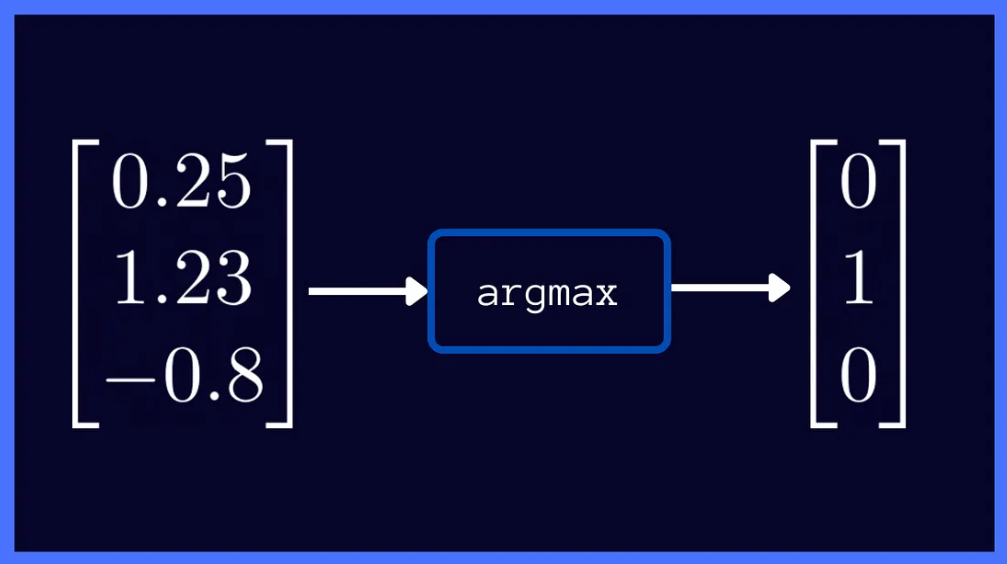
The SoftMax implementation was written from scratch: subtract max score (for stability), exponentiate, normalize.
Step 6: Training with Backpropagation
Training adjusts weights via gradient descent:
Epochs: 500
Embedding Dimension: 100 (configurable)
Learning Rate: Tuned manually
For each context–target pair, the model compares predictions with the true target, computes loss, and backpropagates errors to update W1 and W2.
After 500 epochs, the embeddings started clustering semantically related words.
Step 7: Extracting Word Embeddings
Once training stabilizes, embeddings are retrieved directly from W1.
Example embedding for a word (simplified):
word = “king”
embedding = [0.2, -0.9, 0.6, …]
These vectors can then be used in downstream NLP tasks.
Results & Applications
Even with a relatively small dataset (~298K tokens), the model produced meaningful embeddings:
“king” and “queen” clustered closely.
Contextual words like “cat” and “dog” were near “pet”.
Applications include:
Sentiment Analysis — understanding tone in text.
Machine Translation — mapping similar words across languages.
Information Retrieval — improving search with semantic matches.
Key Takeaways
Building Word2Vec in C++ from scratch deepens understanding of how embeddings actually work.
CBOW is a great choice for small datasets.
With 100-dimensional embeddings and 50 epochs, even a ~298K word corpus can produce usable word vectors.
Final Thoughts
Most developers learn Word2Vec through Python tutorials. Rebuilding it in C++ forces you to confront every detail — from tokenization to backpropagation. It’s a rewarding challenge that gives you both theoretical and practical insights into NLP.
If you’re exploring NLP, I’d highly recommend trying a similar project. The code may be longer, but the learning payoff is huge.
")

")







