
In previous parts of The LLM Journey, we’ve covered:
Part 1: How raw internet text becomes tokens.
Part 2: How neural networks learn to predict the next token.
Part 3: How inference turns those frozen weights into generated text.
Now, let’s ground things in a concrete example: Open AI’s GPT-2. Released in 2019, GPT-2 was the first model that looked recognizably like today’s LLMs. Same architecture, same training loop — just smaller. By revisiting GPT-2, we can see not only how these models are trained, but also why GPUs have become the most coveted hardware in the AI industry.
GPT-2 in Context
Released: 2019 by OpenAI.
Architecture: Transformer-based neural network.
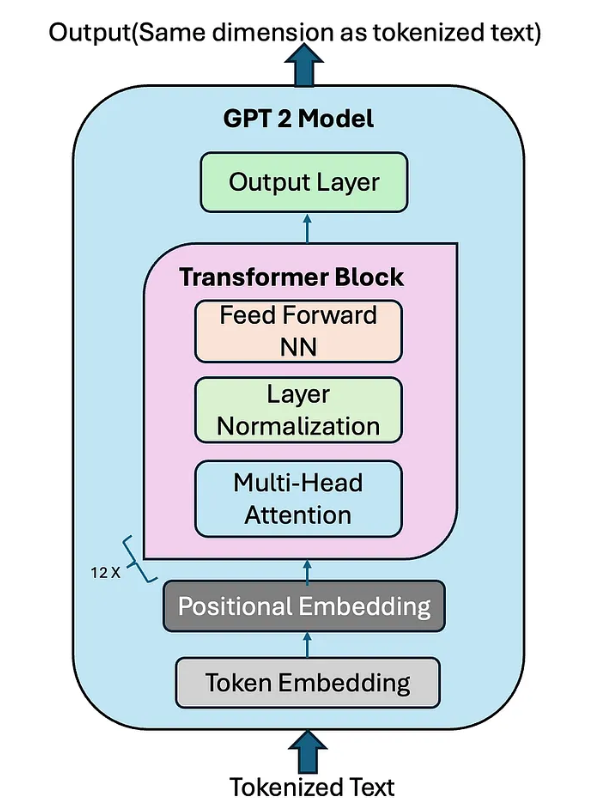
Size: ~1.6 billion parameters (massive then, tiny now).
Context window: 1,024 tokens (vs hundreds of thousands today).
Training data: ~100 billion tokens (vs trillions today).
Back then, GPT-2 was a breakthrough. Today, it’s small enough that researchers can reproduce it on cloud GPUs in a few days for a few hundred dollars.
What Training Looks Like
Training an LLM boils down to iterative updates:
Take a batch of tokens (say, 1 million).
Predict the next token for each sequence.
Compare predictions to ground truth.
Compute the loss (how wrong the model is).
Adjust parameters slightly to reduce the loss.
Each cycle is one optimization step. In the GPT-2 reproduction experiment, the setup ran for ~32,000 steps, each processing 1 million tokens. That’s about 33 billion tokens in total.
At step 20: output looked like random gibberish.
At step 400+: fragments of English appeared, though incoherent.
After full training: fluent text emerged.
The key number researchers watch is loss — steadily decreasing loss = steadily improving predictions.
Inference During Training
To sanity-check progress, training runs periodic inference passes.
At early steps, the model outputs nonsense.
As training continues, local coherence emerges: short phrases that make sense even if whole sentences don’t.
By the end, the model strings together coherent paragraphs.
This iterative improvement is exactly what made GPT-2 so astonishing when Open AI unveiled it.
The Compute Story
Here’s the catch: training GPT-2 wasn’t cheap.
2019 cost: ~$40,000.
Today: ~1 day and ~$600 on rented GPUs. With optimized code, perhaps ~$100.
Why so much cheaper today?
Better datasets: higher quality, less noise → faster convergence.
Faster hardware: Nvidia GPUs like the H100 are orders of magnitude faster than 2019 hardware.
Smarter software: frameworks squeeze every ounce of speed from GPUs.
GPUs: The AI Gold Rush
Training doesn’t happen on laptops. It happens in data centers stacked with GPUs:
Single H100 GPU → specialized chip for parallel computation.
8× H100 node → one machine with eight GPUs.
Many nodes → linked together into massive clusters.
Big tech companies race to secure GPUs because more GPUs = bigger models, faster training, and faster iteration cycles.
This demand is why Nvidia’s market cap soared above $3 trillion — GPUs became the new gold.
Even Elon Musk reportedly ordered 100,000 GPUs for xAI. Each one costs thousands of dollars and consumes massive power — all for the same basic task: predicting the next token at scale.
Why This Matters
The GPT-2 story illustrates two truths:
LLM training is accessible at small scales — researchers can reproduce GPT-2 today for a few hundred dollars.
LLM training is astronomical at frontier scales — GPT-4–class models require thousands of GPUs and hundreds of millions of dollars.
This duality explains why innovation in AI is both democratized (open-source reproductions, smaller models) and centralized (only tech giants can afford trillion-parameter training runs)
Key Takeaways
GPT-2 was the first recognizably modern LLM: transformers, token prediction, massive data.
Training is iterative — billions of tokens processed over thousands of steps.
Loss steadily decreases, while text quality steadily improves.
GPU hardware drives everything — the true bottleneck in scaling AI.
The AI boom is, in large part, a compute gold rush.
Closing Thoughts
GPT-2 may seem small today, but it marked the turning point — the moment the “modern stack” came together. From there, it’s been a story of scaling up: more data, more parameters, more GPUs.
")

")







